In earlier posts, I argued two related ideas:
- Most AI systems today are assistants, not systems of intelligence
- Enterprises don’t fail with AI because models are weak — they fail because intent is unmanaged
This post builds directly on those ideas and takes the next logical step.
If intent is the real abstraction — and if enterprises need repeatable, governed intelligence — then the obvious question is:
Where does intent actually live, and how does it execute?
The Missing Layer: Intent as an Enterprise Asset
Most AI usage today still looks like this:
- A human types a question
- A model responds
- The interaction disappears into chat history
Even when history is saved, it’s still:
- personal
- unstructured
- non-operational
In earlier posts, I described why this breaks down in large enterprises:
- teams repeat the same questions
- successful prompts aren’t shared
- access credentials are implicit or unsafe
- environments don’t exist
- nothing is deployable
So we reframed the problem:
Natural-language intent is not conversation — it is configuration.
Once you accept that, a new design space opens up.
Publishing Enterprise Intents to the Model
One of the key design choices we made was not to treat our client as the “brain.”
Instead, we treat it as a thin, enterprise-aware client that sits between users and large language models.
Here’s the shift:
- Enterprise intents are published via MCP
- The LLM consumes those intents directly
On the other hand, our client
- authenticates the user
- resolves credentials
- selects environment (dev / test / prod)
- forwards the request
- displays the response
In other words:
The intelligence lives in the model.
The discipline lives in the enterprise layer.
This is intentional.
Two Execution Models, One Intent Layer
Once intent is structured and published, execution becomes a choice — not a limitation.
We support two primary patterns.
1. Direct LLM Execution
In this mode:
- The intent is sent directly to the LLM via API
- The model responds with natural language
- The client simply shows exactly what the model returned
This is ideal when:
- reasoning matters more than side effects
- the task is analytical, explanatory, or exploratory
- results don’t need deterministic execution
And still:
- the intent is still shared
- still rated
- still environment-aware
- still credential-safe
2. Code-Generating Execution
In the second mode:
- The intent generates executable code
- That code is run in a controlled runtime
- The result (data, output, side effects) is returned
This is where enterprise use cases light up:
- querying operational systems
- running simulations
- validating scenarios
- orchestrating workflows
Crucially:
- the model never sees raw credentials
- execution happens under the user’s identity
- environment boundaries are enforced
From the model’s perspective, it’s still reasoning.
From the enterprise’s perspective, it’s controlled automation.
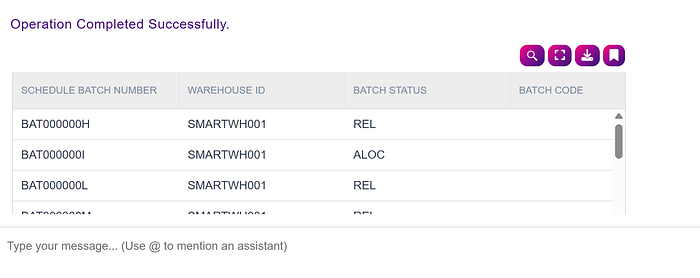
I can, for example, ask:
show all waves in the system
The system will respond:
I can then follow up with:
what did you do?
To which it will respond with the exact code it ran:
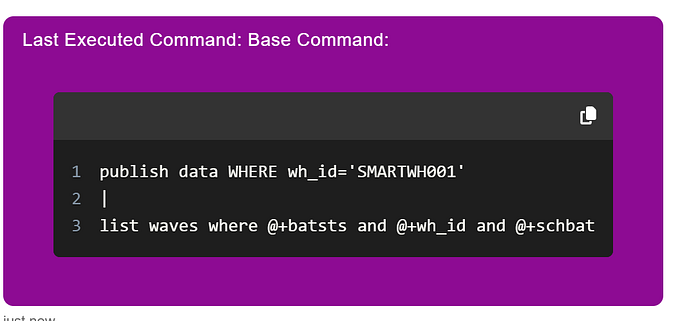
Once intent can be executed safely, a deeper question emerges.
Why should intelligence wait for a human to ask?
From Requests to Reactions: Intent as an Event
The interaction pattern thus far is:
- A human asks
- The system responds
But it still assumes that intelligence is pull-based — someone has to ask.
Enterprises, however, don’t run on questions.
They run on events.
Inventory drops below a threshold.
A shipment misses a cutoff.
A reconciliation fails.
A forecast deviates from plan.
In traditional systems, these are handled through brittle rules engines, cron jobs, or deeply embedded workflows. They are powerful — but opaque, hard to change, and inaccessible to most users.
Once intent is treated as a first-class artifact, another possibility emerges:
Intent doesn’t have to be invoked.
It can be triggered.
Intent as “Whenever… Then…”
In our system, an enterprise intent can be expressed not only as something to ask, but as something to react.
For example:
- “Whenever inventory variance exceeds tolerance, explain why and notify the planner.”
- “If inbound shipments are delayed past SLA, summarize impact and suggest actions.”
- “When forecast error crosses threshold, generate a root-cause analysis.”
These are not scripts.
They are not workflows.
They are declarative intentions, expressed in natural language.
Continuing with the earlier conversation, for example, I can say:
from above when count of waves in ALOC status goes above 10 send email to saad.ahmad[at]smart-is.com
And that’s it! And we are not limited to emails. We can send alerts to mobile devices, or teams channel, etc.
The critical shift is this:
The user defines what matters.
The platform handles when it happens.
Same Intent, Different Invocation
Architecturally, this is not a new system — and that’s the point.


