General-purpose coding models perform well on languages that are well-represented on the public internet. They fail predictably on proprietary or domain-specific languages: hallucinated identifiers, wrong call shapes, and confident reproduction of deprecated patterns. MOCA, the scripting language inside Blue Yonder’s Warehouse Management System, is one of those failure cases, the entire ecosystem (grammar, command catalog, table schema, code examples) sits behind a vendor’s documentation portal, not in public availlable training data.
Smart MocaCoder is the system we built to close that gap. This post walks through the MOCA-specific challenges, the knowledge base we extracted, the tool surface exposed to the agent, the LangGraph deep-agent architecture wrapped around it, and the IDE layer where the generated code actually runs.
A 30-second tour of MOCA
A MOCA program is a sequence of statements joined by operators. The pipe | passes the upstream result set into the next statement as variables (@col_name), executed once per row. A semicolon ; runs the next statement independently with no data flow. An ampersand & runs both sides and unions their result sets.
Each statement is one of: a MocaCommand (create wave where rule_nam = 'X'), an SQL block wrapped in [ ... ], or a (deprecated) Groovy block in [[ ... ]]. There is real control flow - if (...) {...}, try/catch/finally against numeric error codes - and forms for remote (remote(url) stmt) and parallel (parallel(list) stmt) execution.
The grammar surface is small. The vocabulary is what defeats generic agents: every command carries its own argument contract, and the where clause on a MocaCommand is not SQL. A model that confuses those two contexts will fail before the first execution.
Blue Yonder WMS
Blue Yonder (formerly JDA Software) is one of the world’s largest enterprise Warehouse Management System vendors, running distribution centers for major retailers, 3PLs, and manufacturers and MOCA is the scripting layer that orchestrates commands, SQL, and business logic inside it.
The knowledge base
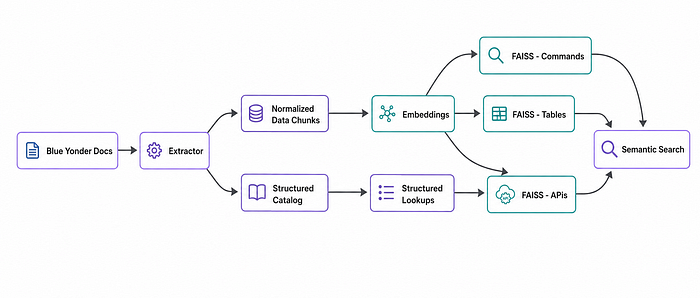
We extracted the published references into a structured catalog. The XML source is parsed, fields are normalized into typed records, and the prose bodies are kept as separate chunks for embedding.

Storage splits along query pattern. A structured catalog holds the typed fields for exact lookups by name. Three FAISS indexes commands, tables, apis - hold dense embeddings (OpenAI text-embedding-3-large) of the doc chunks for semantic search.
Why RAG, not grep-style code search
Modern coding agents (Claude Code, Codex, Cursor etc) lean on grep and symbol search over the user’s coderepository. That model works when the answer is in the code. Here the target isn’t code: a command’s arguments, descriptions, return rows, and exception codes, and a table’s columns and indexes, are all published facts in documentation, not signatures in any reachable source tree.
That shapes the retrieval system in three ways:
- Vocabulary mismatch. Users phrase requests in warehouse-operations language; the catalog name they actually need is often lexically very different. Dense embeddings bridge that gap; literal text search won’t.
- Mixed query shapes. Some lookups are fuzzy (“which command does X?”); some are exact (“schema of
invlod"). FAISS handles the first, the structured catalog handles the second. Grep handles neither well. - Validator-driven loop. Feedback comes from parser responses, not test runs or builds, so the system is closer to compiler-in-the-loop than grep-and-edit. This preserves a retrieval-then-validate architecture instead of iterative file mutation.
The tools the agent has
The catalog is exposed to the agent as eight tools. Vector-search tools accept a list of phrasings rather than a single string, so the agent can probe with several wordings in one call and the searches run in parallel.

Why a deep agent, not a one-shot ReAct loop
A flat ReAct loop is adequate for “fetch the docs for create inventory". It degrades on requests with several moving parts:
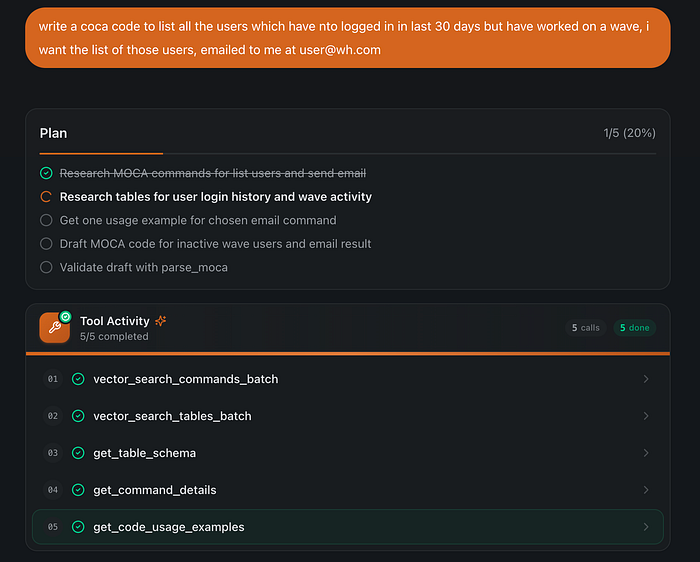
List every user who has not logged in for 30 days but has worked on a wave, and email the list to user@wh.com.
That is four sub-problems (find the user activity table, build the not-logged-in-but-active filter, locate the right email-sending command, compose the payload), and they must compose correctly through pipe operators with matching variable names. The agent needs a plan and the ability to revise it as retrieval reveals new constraints.
We use LangGraph’s deep-agent pattern. It contributes four capabilities on top of standard ReAct:
- Explicit planning. For non-trivial requests the agent writes an internal todo list (4–6 specific, verb-led steps) before tool use, and replans mid-task when retrieval shows a better path. Vague todos like “Generate the code” are explicitly disallowed in the system prompt.
- A focused sub-agent. A
moca-researchersub-agent owns documentation lookups. It only retrieves; it never drafts code or makes architectural decisions. This keeps the primary agent’s context window narrow during code-generation steps. - Per-session checkpointing. Conversation state is persisted per session, so multi-turn interactions survive restarts.
- Live plan visibility. The todo list is part of the graph state, so it streams to the client in real time. The UI renders a checklist that updates as items transition
pending → in_progress → completed, including replanning mid-run when the agent revises its approach.
Use cases in practice
The same architecture serves several distinct query patterns. Three are worth walking through because they exercise different parts of the pipeline.
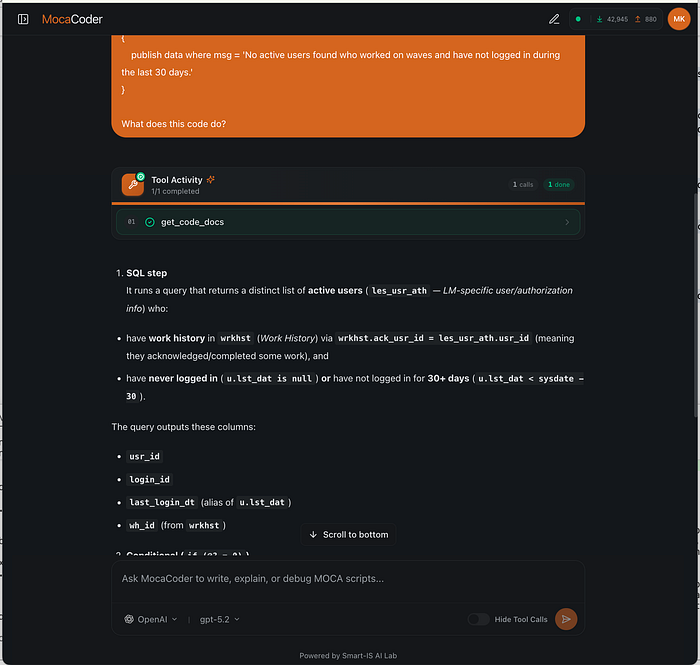
1. “What does this code do?”
A user pastes a MOCA snippet (or a raw SQL fragment) and asks for an explanation.
Internally: This pipeline transforms raw Moca code into grounded, human-readable explanations using structured retrieval and intelligent fallback search.
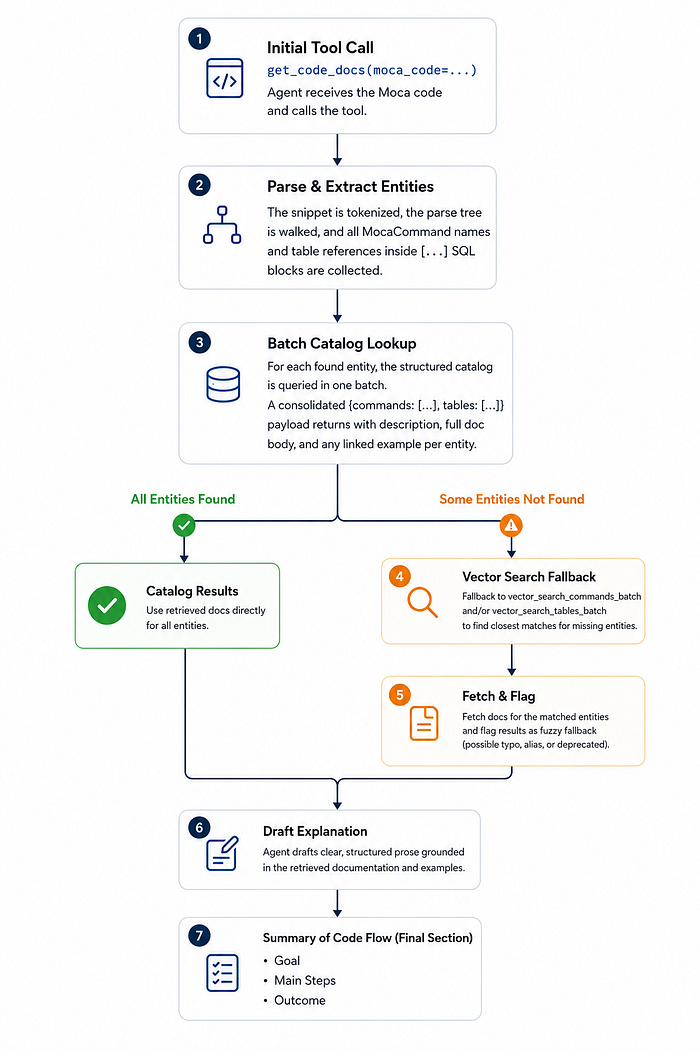
key constraint: the agent never explains from memory. Even when the commands look familiar, get_code_docs is the mandatory first step. That rule earned its place after early versions confidently mis-described well-known commands.
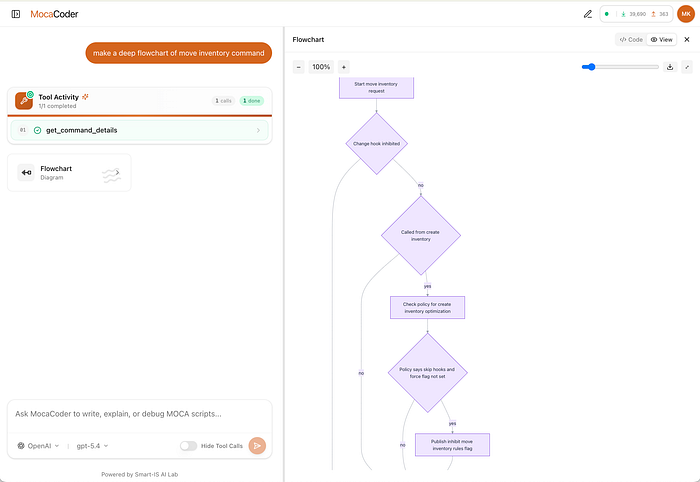
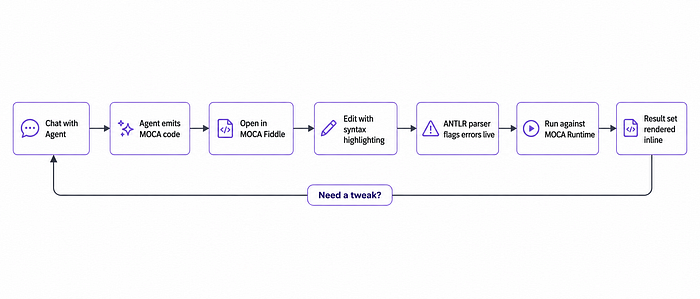
2. Flowchart for a snippet
Instead of a text explanation, the user wants a visual walkthrough of how the MOCA command works. The output is a flowchart.
For shallow requests the agent draws directly from the parsed structure. For a “deep flowchart”, the system first runs get_code_docs to build a complete tree of commands and SQL statements used within the MOCA command. Below is a typical result for a move inventory command.
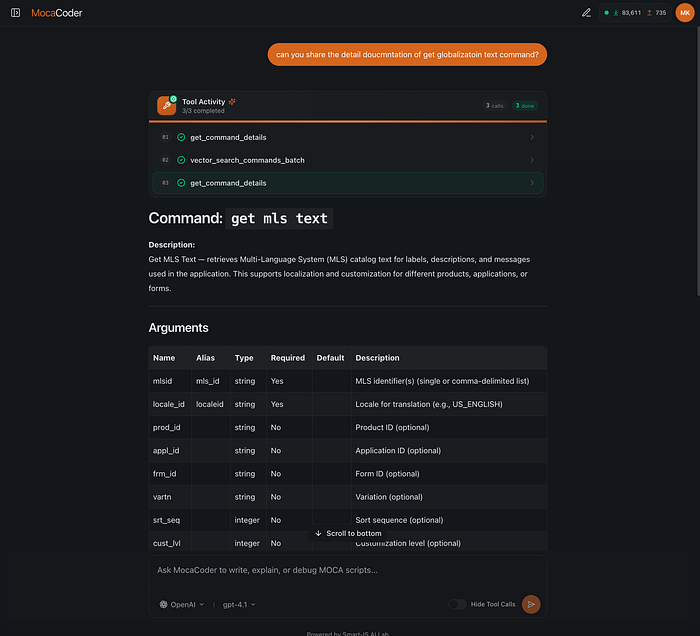
Get Documentation
The system can find relevant MOCA documentation from plain English requests, even when the query is vague or incomplete.
3. Generating non-trivial MOCA code
The third pattern exercises the full pipeline: the user describes intent and the agent produces validated, runnable MOCA.
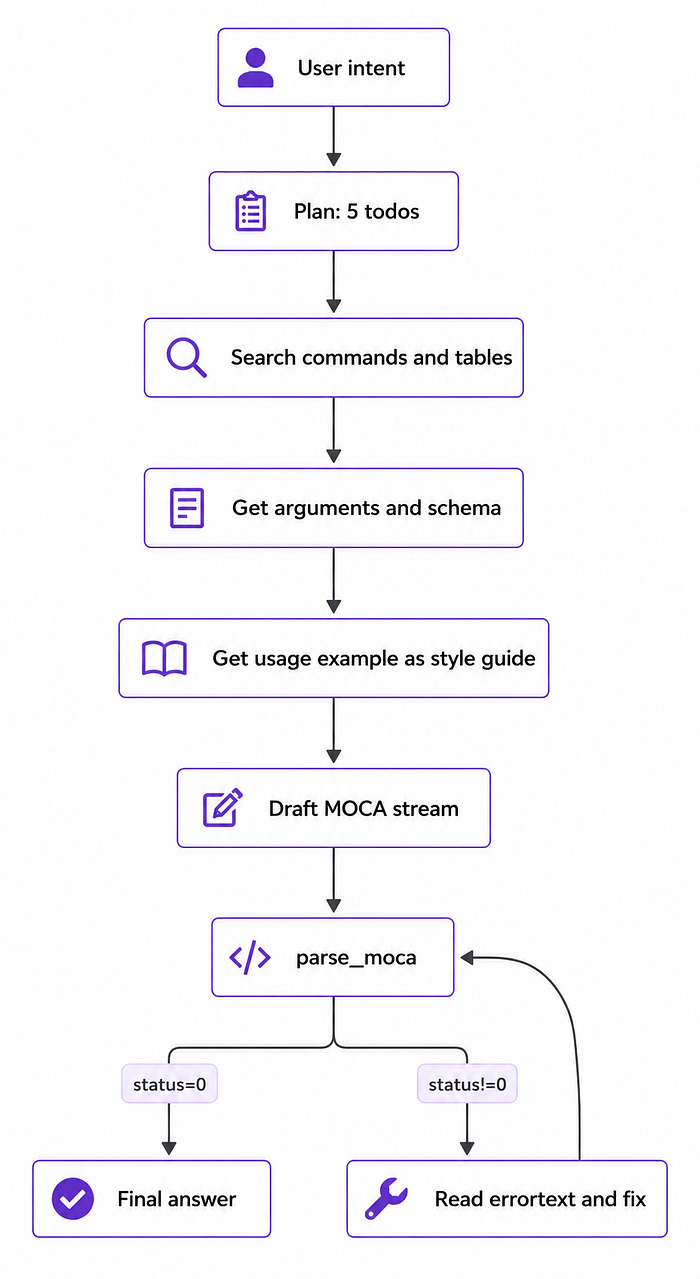
Planning Mode and tool calling inspection
The system exposes its execution plan step by step, allowing users to inspect the tool calls and reasoning used to accomplish the task.
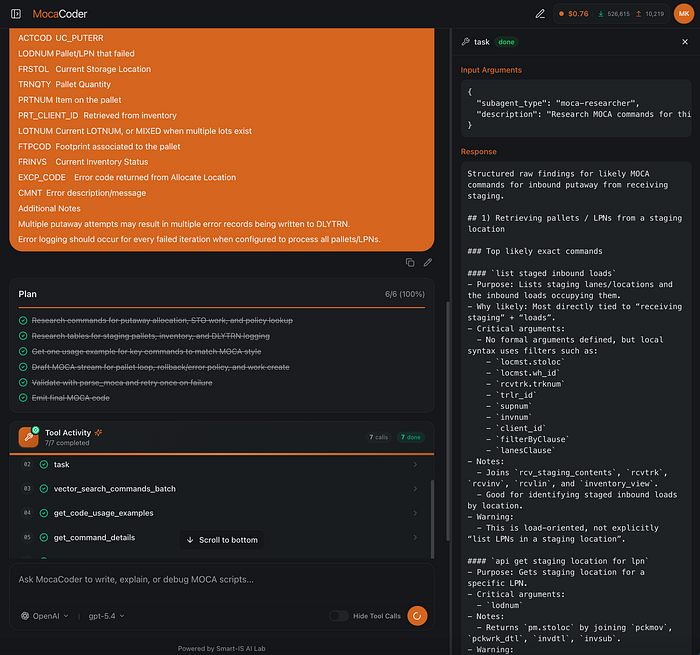
Code Generation and Debugging
Users can execute generated code directly in their test environment, inspect failures, and send errors back to the agent for iterative debugging and fixes.
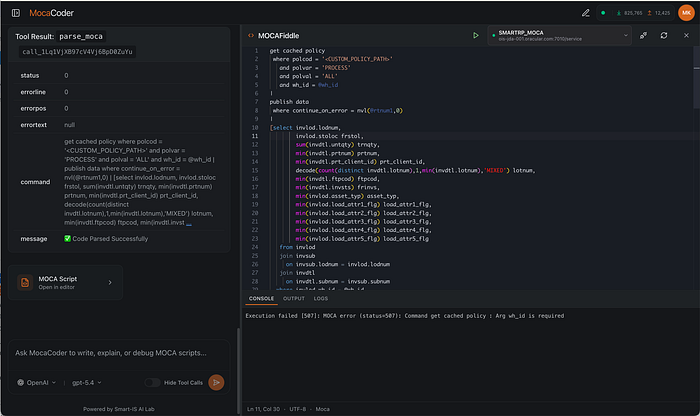
The editor and runtime layer
Generated code is delivered into a Next.js front end with an embedded MOCA Fiddle:
- Monaco editor (the engine behind VS Code) with MOCA syntax highlighting and bracket matching.
- ANTLR-based browser parser for MOCA and MOCA-SQL, enabling live syntax analysis directly in the browser.
- Live execution against a MOCA runtime over WebSocket. The result set is rendered as a table inline.
Guardrails
Three system-prompt rules came directly out of failure modes observed in early iterations:
- Hard stop on parser success. Once
parse_mocareturnsstatus == 0, further validation is forbidden in that turn and genrate final code. - No Groovy fallback. Groovy is deprecated in modern MOCA WMS, but the historical doc corpus contains Groovy examples. The fallback order is fixed at
MocaCommand → SQL. Groovy is never emitted, even when a retrieved example is Groovy-based. - Planning granularity bounds. Too few todos lose requirements; too many fragment context. The prompt requires 4–6 specific, verb-led todos for non-trivial tasks (with concrete entity names, not “research the catalog”) and caps replanning at three iterations per task.
Trade-offs
- Token volume. A non-trivial generation typically consumes 30k-80k tokens across plan, batched searches, detail lookups, draft, parse, and (often) one fix-and-retry. Most of those tokens are cache reads, which the provider serves at a steep discount, but the run is still chatty by design.
- Latency. Plan → search → draft → validate is slower than direct generation. Streaming hides some of it, end-to-end response time is on the order of tens of seconds.
Generalizing the pattern
The MOCA-specific components are the grammar rules, catalog schema, and parser. The surrounding architecture is reusable: extract structured documentation from vendor sources, build both an exact-match catalog and a vector index, expose them through a focused tool layer, wrap the system with a deep agent, and keep a real validator such as a compiler, parser, type-checker, or linter in the loop. The same approach applies to other proprietary scripting systems, including ERP DSLs, low-code platform expressions, and vendor configuration languages where rich documentation and a runnable validator are available.
Conclusion
A general-purpose coding model has zero useful priors for MOCA - the language isn’t in its training data, and “looks plausible” and “actually parses” are different distributions. The way around that gap turned out not to be a bigger model but a tighter system: an extracted, structured catalog of every command and table; a small, focused tool surface (semantic search + exact lookups + the real parser); a deep-agent loop that plans, retrieves, drafts, and validates with explicit guardrails on each step; and a UI that surfaces all of it - the plan, the tool calls, the generated code - in one editable, runnable surface.
The MOCA-specific pieces are the grammar, the catalog, and the parser. Everything around them - retrieval shape, deep-agent loop, validator-in-the-loop, transparent tool calls, in-browser runtime - is a pattern that holds for any proprietary language with dense documentation and a runnable checker. If your team owns a DSL, an ERP scripting layer, a configuration language, or any other dialect that the public crawl missed, the same recipe applies, and most of the engineering work is in the corpus extraction, not in the agent.
If your team is exploring enterprise AI — whether for a domain-specific coding agent like this one or other production use cases — we’d welcome a conversation. Get in touch at https://www.smart-is.com/contact/
Originally published at Medium.