Unlocking Efficiency: Expert Tips and Tricks for RedPrairie™ WMS (Technical) from Leading RedPrairie Consultants and Blue Yonder JDA Experts
Index
- Autonomous Nested Transactions in RedPrairie
- Do not store environment specific data in the database
- Getting SQLServer deadlocks?
- An integrator query keeps showing up as bad query for oracle?
- Always use base-36 sequences
- Shortcut to run RedPrairie command line tools on Windows
- Create multiple environments from same installation
- How to turn off Windows Popup when MOCA crashes?
How to Turn Off Windows Popup When MOCA crashes?
This is important because this is a server; we should not get popups on the server when an error occurs. Please refer to MSDN Article for details.
- Change registry key HKLM\Software\Microsoft\Windows\WindowsErrorReporting to add a DWORD key “DontShowUI” with value of 1.
- If visual studio is installed on the server, disable just in time debugging. Go to “Tools” then “Options”. Then go to “Debugging” and then “Just in Time”. Disable all checkboxes
Verify that popups will not be displayed on crash.
- Open a command prompt on the server and run env.bat
- Run msql -S
dump core
/
- Make sure it simply returns 204 and does not show a popup
Autonomous Nested Transactions in JDA/BY
The concept of an autonomous transaction is that the parent transaction commits and rolls back but within that transaction, we want to do another transaction that will commit/rollback independently. For example:
update row in table 1 Now start a new transaction update row in table table2 commit End nested transaction Now in parent transaction, even if it rolls back, table2 update is still committed.
Most common use of this is for logging messages. For example RedPrairie integrator sl_msg_log or sl_async_evt_queue can get data even if parent transaction rolls back.
In Oracle, this is a native feature; for example, you can do following within MOCA if backend is Oracle.
[
declare
pragma autonomous_transaction;
begin
some pl/sql code which updates the database
;
commit;
end;
]
There is no straightforward way of doing this in SQLServer. Some options were:
- Send a message to another daemon process which interprets the message and commits to the database. In previous versions integrator daemons provided this functionality
- Do a remote command to yourself as 127.0.0.1 and do a commit in that transaction
Now as 2011, MOCA provides this natively for all databases. A MOCA Command can have a new tag called “transaction” If that is set to “new” then the work within the command will be done in its own commit context, e.g.
<command>
<name>change ossi job log aut</name>
<description>Change an entry into the job log in own commit context</description>
<type>Local Syntax</type>
<transaction>new</transaction> ...
To test it, you can do something like:
- Open two msql sessions
- In session 1, turn off auto-commit
- Now in session 1, execute an update statement, then execute a MOCA command that has its own transaction, e.g.
[update sl_sys_def set sys_descr = 'Transactions to the ASI and Mapics system!!' where sys_id = 'ASI-MAPICS']
;
/* Following is a command with New transaction */
change ossi job log aut
where uc_ossi_job_seq = 1
and uc_ossi_module_seq = 0
and uc_ossi_action_seq = 0
and uc_ossi_err_code = 12
and uc_ossi_err_descr = 'T1'
- In session 2, query sl_sys_def for ASI-MAPICS system; you will not see the changed description because auto-commit was off
- In session 2, query for effect of the autonomous MOCA command, you will see the change
- In session 1, rollback or commit will affect the update statement but not the autonomous MOCA Command
This is a very useful feature. You do not need to log to a file; instead you can use database tables for logging which is much more efficient. For example we always put a general purpose log table to keep track of long running jobs and tasks. It may come in handy to log daily transactions in case of certain failures. I have not really compared the oracle autonomous transaction vs. MOCA autonomous transaction to see which is more efficient. If you are on oracle, you could stick with PL/SQL autonomous transaction but this is the only option for SQLServer.
Do Not Store Environment Specific Data in the Database
Any given JDA/BY environment typically needs to maintain links to several other environments for example:
- Integrator settings for host/port, queue names, folders
- Parcel Server connection information
- Archive instance connection information
Whenever I am engaged in a project, I always setup an absolute goal that none of such data elements be stored in the database. Instead these should be environment variables. If we are able to achieve that then the task of copying database from one environment to another becomes a simple task which greatly simplifies the overall footprint of RedPrairie. Such settings should instead be turned to environment variables that would be stored in JDA/BY registry. Make sure all environment variables are prefixed by “UC_”. You can easily achieve this goal:

Getting SQLServer Deadlocks?
First it is very important to understand what is a deadlock. Many people wrongly consider a deadlock as a typical locking condition. Read this MSDN article to get a better understanding SQLServer has a concept of lock escalation where a lock that starts with a row-level lock can escalate to a page level lock. So even if you have architected an application properly the exact sequence of locking becomes un-predictable because you do not know what you are locking because data within a page is unpredictable. In later versions of SQLServer, it is possible to disable this lock escalation. In all frequently used tables I always disable the lock escalation. You can use following script for a given table:
[sp_indexoption @table_name, 'AllowRowLocks', true] ; [sp_indexoption @table_name, 'AllowPageLocks', false] ; [alter table @table_name:raw set (lock_escalation = disable) ]
Thanks to the power of MOCA piping, you can easily run this for the tables you want to run it for, for example:
publish data where table_list = 'coma-separated-list-of-tables'
|
{
convert list where string = @table_list and type = 'L'
|
{
[commit] catch(@?)
;
[sp_indexoption @retstr, 'AllowRowLocks', true]
;
[sp_indexoption @retstr, 'AllowPageLocks', false]
;
[alter table @retstr:raw set (lock_escalation = disable) ]
;
publish data where table_name = @retstr
}
}
Just a word of caution that SQLServer maintains a list of locks so after this change you will get a lot of locks (this is different from Oracle — but that is a different discussion, just know that Oracle does not have an issue with so many locks). But you pretty much have to do it.
An Integrator Query Keeps Showing up as Bad Query for Oracle?
Those tasked with monitoring SQLs on Oracle often complain about one specific query from integrator:
select ...
FROM sl_evt_data ed, sl_ifd_def id, sl_sys_comm ssc, sl_ifd_sys_map_data ismd, sl_ifd_data_hdr sidh
WHERE id.ifd_id = sidh.ifd_id
and id.ifd_ver = sidh.ifd_ver
and ssc.sys_id = ismd.sys_id
and ssc.comm_mode_cd = :1
and ssc.comm_dir_cd = :2
and ismd.sys_id = :3
and ismd.ena_flg = 'T'
and ismd.blkd_flg = 'F'
and ismd.comm_mode_cd in ( :99, 'SYNCE' )
and ismd.ifd_id = sidh.ifd_id
and ismd.ifd_ver = sidh.ifd_ver
and ismd.evt_data_seq = sidh.evt_data_seq
and nvl(ismd.comm_mthd_id, ssc.comm_mthd_id) like :5
and sidh.sys_id = :99
and sidh.snd_dt is null
and nvl(sidh.proc_err_flg,'F') = 'F'
and sidh.evt_data_seq = ed.evt_data_seq
and ed.evt_stat_cd = 'IC'
ORDER BY
...
This query is looking for events in a specific status (IC) but Oracle ends up not favoring sl_evt_data as starting table because of the number of rows in this table. This query itself is not a bad query All we need to do is use the proper optimization tools In this case Oracle sees a large table and wants to go by a smaller table because it does not know that even though sl_evt_data is a large table but there are only a few rows in the status in question. To help oracle make the right choice, create a histogram on the evt_stat_cd column.
Always use Base-36 Sequences
RedPrairietm sequences are defined in the sysctl table. They have a flag which can turn them from base 10 to base 36. I always put most of the heavily used sequences to base-36 when a project starts. Some sequences where this is especially useful are:
- wrkref (pckwrk table)
- cmbcod (pckmov table)
- ship_id (shipment table)
- ship_line_id (shipment_line table)
- dtlnum (invdtl table)
- ctnnum (pckwrk table)
- Strongly consider for subnum (invsub table) and lodnum (invlod table)
- Sequences for transaction history tables are already base-36, for example dlytrn_id, etc.
- Integrator tables do not have string columns as PK so cannot turn them to base-36 but these are pretty long (12 digits)
Never under-estimate the frequency at which these sequences can be consumed and never ever let someone tell you that “these will be in archive by the time they roll around”. Archive instance has the same restrictions so moving the problem to archive does not really address the core issue. Following are some sequences where I have actually seen this issue:
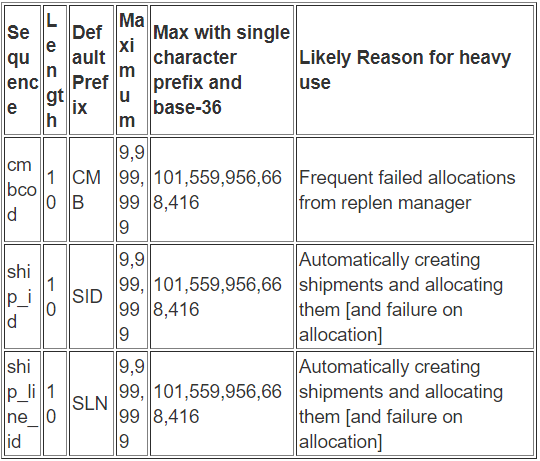
Just to put it in perspective, lets say you consume 10,000 sequence numbers a day, time till you run out of numbers for 7 characters is as follows:

If you are already live and now want to consider this change then you should find the base-36 equivalent number for the current sequence value and increase the value to that. Then change sequence to base-36. You will have a huge gap in sequence numbers but you will most likely still have much more room to grow. If you are very close to using up the numbers, then change your prefix to a higher valued prefix for example SLN can become SLP (or take the opportunity to go from 3 character prefix to a single character) then start over as a new base-36 sequence.
Shortcut to Run RedPrairietm Command Line Tools on Windows
Several RedPrairie tools, like mbuild, mgendoc, rollout process require a command prompt. Rather than running “env.bat” every time, I place a shortcut on my desktop for each environment I am supporting. This way I can get an environment right away. In order to create such a shortcut, follow following steps:
- Open windows “cmd” window.
- “cd” to the installation directory, i.e. parent directory of your LES folder.
- Run “moca\bin\servicemgr -e environment name -dump”. This generates a file called “env.bat” in this directory.
- Now right click on your desktop and create a shortcut to “cmd /k c:\redprairie\<env>\env.bat”
- Set the size of the window and scroll properties
- Set a name for the window
Create Multiple Environments from Same Installation
A JDA/BY environment is defined as code + data. It is possible to create multiple environments from same code or have different code bases point to the same data. Both of these concepts come in handy. Before I discuss this, I want to explain the concept of “rptab” file which is part of Moca NG framework. On Windows, this file is in c:\programdata\RedPrairie\server and contains all environments on this server. The text file has multiple lines where each line has 2 or 3 fields (3rd is optional) delimited by “;”.
- Name of the environment
- LES folder
- Optional: Path to registry file. If not provided it is assumed to be in data subfolder under LES and the name is assumed to be “registry”
Registry file has following entries that setup the environment:
- URL
- RMI-PORT:
- port
- classic-port
- Database section
With these two concepts, we can use the same set of source code and create multiple environments from it, i,e. dev environment and test environment could share the software but would have different databases. You can follow following steps to, for example, install software once and create different environments, e.g. dev and test:
- Install the software (e.g. c:\redprairie\WM201214)
- Modify the rptab file to create a new entry for your new environment.
- If you want a separate LES folder, then specify that otherwise specify the same LES folder as WM201214
- Specify the path to registry file. If you are sharing the LES folder, then this is important
3. Optional: If you want a different LES folder in test then create a new folder for your environment ( e.g. c:\redprairie\test\LES ) and copy c:\redprairie\WM201214\LES to this new location
4. Change the registry file for your new environment for URL, RMI-PORT, classic-port, and database section
5. Use c:\redprairie\WM201214\moca\bin\servicemgr.exe to create a new service and a new shortcut
Another variation may be to test the same data from two different code bases(what I described above is same code for different data). If you do this, make sure only one environment is running at one time
- Point the registry in both environments to the same database
Originally published on saadwmsblog.blogspot.com




One thought on “Common Tips and Tricks for RedPrairie(tm) WMS (Technical)”
Thanks Saad!
Jesus Rendon